来源:华尔街见闻
据报道,Q*可能具备GPT-4所不具备的基础数学能力,或意味着与人类智能相媲美的推理能力,网友推测,这可能代表OpenAI朝着其设定的AGI目标迈出了一大步。随着OpenAI CEO奥特曼回归,宫斗大戏告一段落,但仍留下了许多未接的谜题。其中最为关键的,就是当初奥特曼为何会被董事会解雇。
昨日,有媒体透露,就在奥特曼被开除四天前,几名研究人员向董事会发出了一封信,警告一项强大的AI发现(Q*)可能威胁全人类。此外,OpenAI CTO Mira Murati此前在致员工的内部信件中提到了一个代号为“Q*”的项目。据她称,该项目为“董事会对奥特曼的一系列不满中的因素之一”。
据多家媒体猜测,Q*让OpenAI实现AGI的步伐大大提速,但奥特曼可能没有和董事会详细披露Q*的进展到底有多大,这也符合董事会在解雇奥特曼时所说的“在与董事会沟通时没有始终保持坦诚”。
就在被解雇之前,奥特曼还在公开活动中表示:
“在OpenAI的历史上,我们已经取得了4次突破,最近一次是在过去的几周里。当我们把无知的面纱撕下,把发现的前沿向前推进时,我就在房间里。”
所谓的第四次突破,指的可能就是Q*项目。
什么是 Q*?
什么是Q*?
Q*读作Q star,目前OpenAI内部没有任何关于Q*的详细信息流出。
据一些业内人士猜测,它可能是是机器学习算法Q-Learning(Q学习)的同义词,也许是OpenAI借助Q学习算法打造的新模型的代号,也许是一个相关的项目名称。
科技博客PC Guide指出,OpenAI使用的Q*指的大概是贝尔曼方程中的最优值函数,Q*可能代表OpenAI找到或接近了效率优化算法的最优解。
根据天风证券分析师孔蓉的说法:
Q学习是一种基于强化学习的算法,用来在马尔科夫决策过程中求解最优控制问题。它的目标是通过学习最优策略,使智能体在未知环境中做出最佳选择。
Q学习依据贝尔曼方程更新状态-动作对应的Q值,逼近最优值函数。智能体通过与环境交互,观察到新的状态和奖励,来更新执行各个动作的Q值。
所谓贝尔曼方程,也被称为动态规划方程,是指数学家理查德·贝尔曼提出的用于解决复杂多阶段问题的公式,通过求解该方程可以找到最优值函数和最优策略。
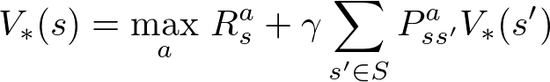
运行算法的人(或计算机)可以输入一个目标函数,例如“旅行时间最短、成本最低、利润最大、效用最大”等。然后,算法将决定采取何种最佳行动来实现预期结果。
简单来说,Q学习可以通过探索所有可能的路径,学习到通往预期奖励的最短路径(最短路线),通过试错找到更优化的路径,并随着时间的推移达到优化状态,每次都做出更好的决策。
据媒体报道,在奥特曼被解雇之前,OpenAI在内部对Q*进行了演示,显示Q*能够解决小学程度的数学问题。
虽然完成小学数学题听起来没什么出色之处,但需要强调的是,包括GPT-4在内,世界上最先进的大语言模型通常都更擅长基于语言的任务,即使面对加减乘除这样的基础数学都会犯错误。
如果真如报道所说,Q*有能力处理数学问题并给出明确答案,即使只是小学数学,那也意味着巨大的飞跃。基础数学能力或意味着与人类智能相媲美的推理能力,也意味着OpenAI朝着其设定的AGI目标迈出了一大步。
另外据一些网友猜测,Q*背后的模型模型可能已经具备自主学习和自我改进的能力,或者能够通过评估其行为的长期后果,在广泛的场景中做出复杂的决策,可能已具备轻微自我意识。
最乐观、或者最可怕的假设就是,OpenAI已经完成了打造AGI的基础工作。
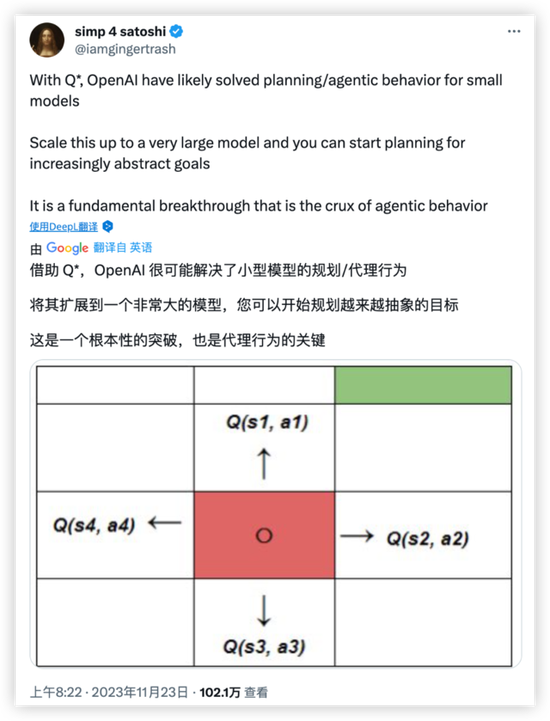
听起来很离谱,但确实有可能是真的。
就在一个月前,华尔街见闻曾转载过MIT科技评论对OpenAI首席科学家Ilya Sutskever的专访,他当时称,ChatGPT可能已经有了意识。
Q*会产生哪些后续影响?毁灭人类?
目前,OpenAI所给出的官方回应是,奥特曼被解雇,与公司的研究进展无关。
但仍然挡不住网友天马行空的猜想和阴谋论。
一位Reddit网友说,对于AI界而言,Q*的出现可能就像是,一个人想敲石头生火,敲了几年都没什么成果,结果上礼拜石头突然敲出火星了。

另一位Reddit网友已经开始想象AGI诞生之后的场景了:
AI开始发明东西,破解互联网上的一切加密,写出以人类的数学能力理解不了的程序...

不过,理性地想,AGI的诞生大概率不会这么快。Q*可能只是人类以后漫长探索征程的开始。
根据天风证券分析师孔蓉的观察,OpenAI近期的招聘进程表明其在进一步增强强化学习系统的决策能力。
OpenAI近期持续引入强化学习和决策算法研究人员。23年7月份新引进的研究员Noam Brown,开展多步推理和多智能体互动方面的研究。
Noam Brown 此前参与发表的工作将语言模型与规划和强化学习算法结合,大幅提升了AI在复杂策略游戏中的表现,开发出第一批在德扑无上限游戏中击败顶级玩家的AI。
OpenAI 近期于 5 月份发布的研究也表明,调整训练方式和引入更大规模的监督数据,将会显著提升强化学习系统的数学推理能力。OpenAI 引入针对过程的强化学习监督,进一步提升大模型在数据推理与计算的准确性。
据孔融推测,强化学习与决策算法进步或带来Q*大模型能力突破,GPT4 + 强化学习和决策算法,或能实现更强的AI Agent能力。